Gender aware spoken language translation Arabic To English
Publications ·During my work at Microsoft Research Lab in Cairo, we were brainstorming for research projects related to our work Skype Translator for the upcoming summer internship.I got the idea of making a machine translation system that keeps the lost gender information while translating from Arabic To English.
Introduction
Leverage demographic information like gender information that can be extracted from speech to improve accuracy of machine translation models.
Example on English to Arabic and English to French:
I am sure from a female speaker => انا متأكدة
I am sure from a female speaker => je suis certaine
Without the proposed system the above example would be translated depending on the bias in the input corpus, the corpus might be biased to male translations forcing the system to give higher probability to male adjective.
Motivation
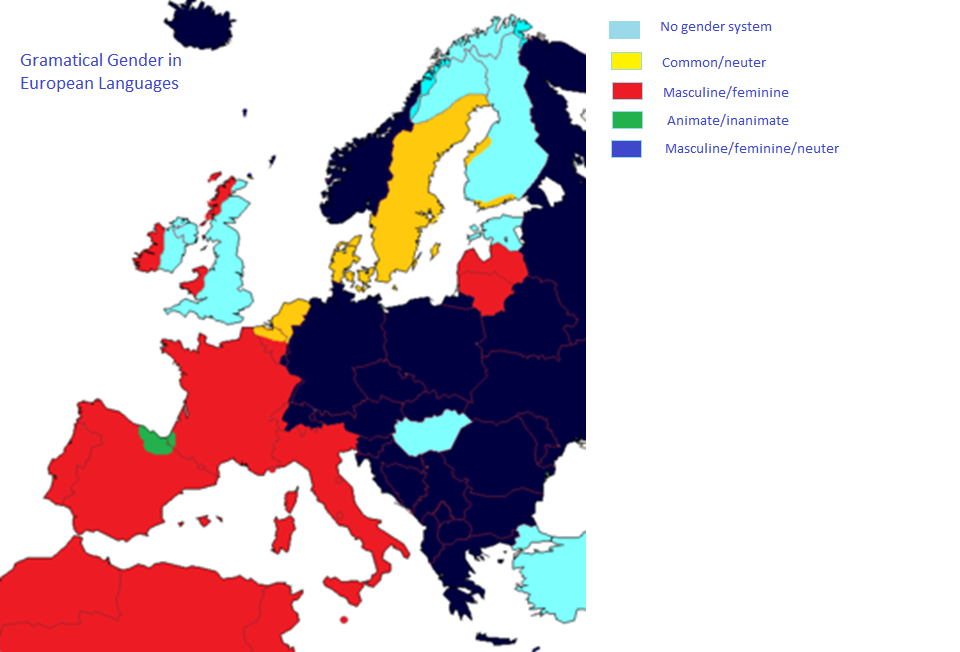
English [and about half the world’s languages] do not have strong grammatical gender agreement requirements.
- Except for “he/she/it and his/her/its
The other half, including Arabic and most European languages have a gender system.
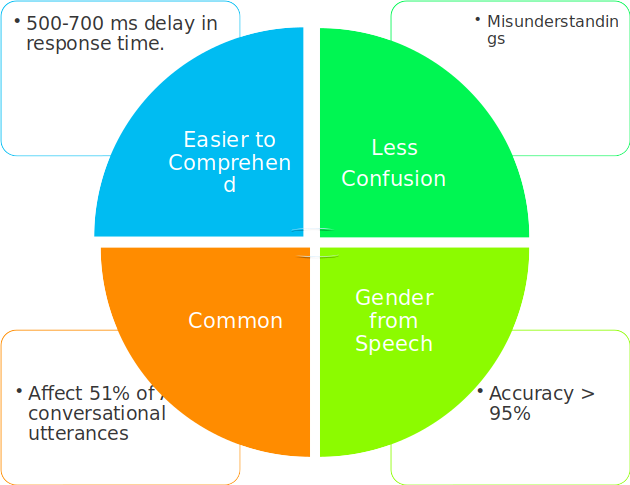
Also fixing gender biases in the output of a Spoken language translation system would give a better user experience and will reduce the confusion.
System Diagram
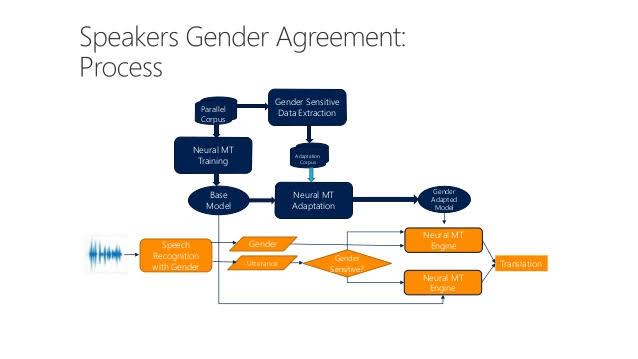
Technical Details
Add a token during training to indicate the genders of the speaker and listener. For example : -sf- to denote speaker female and -lf- to denote listener female
POS Tagger
We used a POS Tagger to determine gender of target sentence and to put its label on the source language for training. This step is just used to generate the data used for the training of the NMT system parallel Data.
POS Tagger Results on Arabic for Gender Extraction
| Metric | Speaker is a male | Speaker is a female | Listener is a male | Listener is a female |
|---|---|---|---|---|
| Precision | 80.00% | 100.00% | 63.15% | 93.33% |
| Recall | 19.04% | 25.00% | 11.65% | 51.85% |
\newline
Data Labeling on Parallel Text Data
We used the POS Tagger on 1.5 million sentences from subtitles data. About 150k sentences were tagged with a gender. If the tagger couldn’t determine the gender we didn’t add the token.
Test Set
We created 3 test sets:
- First one was short sentences and focused only on adjectives and gender.
- Second one was a random 2k sentences from the subtitles data which we tagged manually.
- Third one was only the labeled sentences from the random 2k
Model Architecture
We used an attentional encoder decoder model with Bidirectional LSTM.
Bleu Scores
| Model | Gender only set | Random 2k | Labeled data within random 2k |
|---|---|---|---|
| Before Adaptation | 16.48 | 18.36 | 18.8 |
| 1 Epoch, α=0.001 | 17.95 | 18.26 | 20.47 |
| 2 Epochs, α=0.001 | 16.07 | 17.98 | 20.38 |
| 5 Epochs, α=0.001 | 15.12 | 17.97 | 21.16 |
| 10 Epochs, α=0.0001 | 21.8 | 14.07 | 19.27 |
Collaborators
- Ahmed Y Tawfik
- Mahmoud Khaled
- Hany Hassan
- Aly Osama