Inference-time factuality improvement in LLMs: from layer contrasting to deep-thinking tokens
Paper Review ·LLMs hallucinate (Huang et al., 2025). They generate text that sounds right but isn’t. Most fixes require retraining or plugging in external knowledge. But a growing set of papers asks a different question: can we make models more truthful just by changing how they decode?
This post covers five methods that do this: DoLa, SLED, DELTA, Lookback Lens, and Think@n. None of them touch the model weights. None need extra data.
What’s wrong with standard decoding?
When an LLM generates text, it takes the hidden state from its last layer, projects it to vocabulary space, applies softmax, and picks a token.
This is simple but has known problems (Stahlberg & Byrne, 2019):
- Sampling noise can push low-probability wrong tokens through.
- The model sometimes over-attends to recent tokens and loses track of the original input.
- The softmax bottleneck can suppress correct tokens that have lower probability.
Training fixes like RLHF can make things worse by encouraging sycophancy (Gekhman et al., 2024). RAG helps but adds a lot of complexity.
The methods below all start from one observation: different transformer layers encode different levels of factual knowledge. By looking at how predictions evolve across layers, we can get more truthful outputs.
1. DoLa: decoding by contrasting layers
(Chuang et al., 2024) (ICLR 2024)
Factual knowledge in LLMs tends to be localized in specific transformer layers. DoLa exploits this by subtracting an early layer’s predictions from the final layer’s predictions.

The idea
In a transformer with \(L\) layers, each layer \(l\) can produce a next-token distribution \(p_l\) by projecting its hidden state through the vocabulary head. Standard decoding uses only the last layer \(p_L\).
DoLa computes:
\[p_{\text{DoLa}} \propto \text{softmax}\left(\log p_L - \log p_l\right)\]where \(l\) is a dynamically selected early layer.
Why does subtracting help? Early layers capture syntax and surface patterns. Later layers refine those into factual associations. The subtraction removes the surface-level noise and keeps the factual signal.
Picking the right early layer
For each token, DoLa picks the layer with the highest Jensen-Shannon Divergence from the final layer. This targets layers where the most factual transformation is happening, rather than using a fixed layer that might not be informative for every token.
Results
- +12-17 points on TruthfulQA for LLaMA models
- Gains on StrategyQA and GSM8K
- Minimal added latency
2. SLED: self logits evolution decoding
(Zhang et al., 2024) (NeurIPS 2024)
DoLa contrasts two layers. SLED uses all of them.
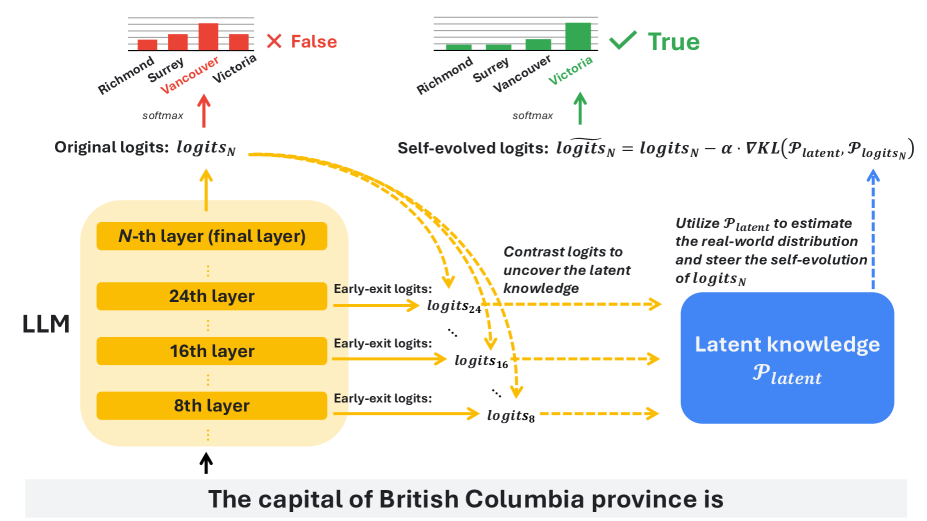
The idea
SLED projects the hidden state from every layer through the vocabulary head, producing a trajectory of distributions:
\[\{p_1, p_2, \ldots, p_L\}\]This trajectory shows how the model’s predictions evolve from shallow guesses to factual assessments.
Instead of picking two layers to contrast, SLED computes a weighted combination of all layer distributions. It frames this as an approximate gradient step that pushes the output distribution toward factual accuracy.
You can think of it as the model asking itself: “based on how my predictions evolved across all my layers, what should I actually output?”
Why it works better than DoLa
DoLa picks two snapshots. SLED uses the full trajectory. The gradient formulation is also more principled since it doesn’t require the somewhat arbitrary selection of a premature layer.
Results
- Outperforms DoLa across Gemma, Qwen, Mixtral (1B to 45B parameters)
- State of the art on TruthfulQA, FACTOR, StrategyQA
- Negligible latency overhead
3. DELTA: contrastive decoding via input masking
(Huang & Chen, 2025) (2025)
DELTA takes a different angle. Instead of contrasting across layers, it contrasts across inputs: run the model on the full prompt, then run it again on a masked version of the prompt, and subtract.

The idea
- Run the model on the full input. Get output distribution \(p(x_t \mid c)\).
- Mask random tokens in the input. Get output distribution \(p(x_t \mid \tilde{c})\).
- The masked version lacks grounding information, so it hallucinates more. Subtract its logits from the original.
This is related to context-aware decoding (Shi et al., 2024), but DELTA uses random partial masking rather than removing the context entirely. That makes it better at targeting hallucinations that come from contextual ambiguity specifically.
Results
- +3 points on SQuAD v1.1, +6 points on SQuAD v2
- +10 points on SQuAD v2 no-answer exact match
- Gains on TriviaQA and Natural Questions
4. Lookback Lens: are you even looking at the context?
(Chuang et al., 2024) (EMNLP 2024)
The first three methods modify the output distribution. Lookback Lens does something different: it detects hallucinations by watching where the model’s attention goes.
The hypothesis is simple. When a model hallucinates, it stops paying attention to the input context and starts attending to its own generated tokens.

The lookback ratio
For each attention head \(h\), compute:
\[r_h = \frac{\sum_{i \in \text{context}} \alpha_{h,i}}{\sum_{i \in \text{context}} \alpha_{h,i} + \sum_{j \in \text{generated}} \alpha_{h,j}}\]High ratio means the model is grounding its output in the input. Low ratio means it’s talking to itself, which usually means it’s making things up.

What they found
A simple linear classifier on these lookback ratios detects hallucinations about as well as methods that use full hidden states or entailment models.
A detector trained on a 7B model also works on a 13B model without retraining, which suggests the attention patterns that signal hallucination are consistent across model sizes.
For mitigation, they use classifier-guided decoding: penalize tokens that the classifier flags as likely hallucinations. This cuts hallucination by 9.6% on XSum summarization.
How it relates to DoLa and SLED
Lookback Lens comes from the same first author as DoLa (Yung-Sung Chuang), and the two papers complement each other. DoLa and SLED fix the output distribution to be more factual. Lookback Lens detects when hallucination is happening. You could combine them: use Lookback Lens to spot risky tokens, then apply stronger layer-contrasting corrections at those positions.
5. Think@n: it’s not about length, it’s about depth
(Chen & others, 2026) (Google, 2026)
This one came out of work on reasoning models like DeepSeek-R1. The question: do longer reasoning chains actually produce better answers?
The answer is no. What matters is how deeply the model processes each token.

Deep-thinking tokens
A deep-thinking token is one where the model’s internal prediction changes a lot across layers before settling on an answer. The Deep-Thinking Ratio (DTR) measures what fraction of tokens in a sequence are like this:
\[\text{DTR} = \frac{|\{t : \text{JSD}(p_l(x_t), p_L(x_t)) > \tau \text{ for some } l\}|}{T}\]This is the same kind of layer-wise divergence that DoLa and SLED exploit. Tokens where logits diverge across layers are the ones where the model is doing real work.
The numbers
Raw token count correlates negatively with accuracy (\(r = -0.544\)). More tokens, more likely wrong.
DTR correlates positively with accuracy (\(r = 0.683\)). More deep thinking, more likely correct.
This validates the premise behind DoLa and SLED from a completely different angle, which I think is the most interesting part of this paper.

The Think@n strategy
Given a budget of \(n\) samples:
- Generate short prefixes (just 50 tokens).
- Estimate DTR from these prefixes.
- Only continue generating the highest-DTR candidates.
This matches or beats standard self-consistency while cutting inference costs by about 50%.
Both Think@n and Lookback Lens give you cheap signals about generation quality: one watches attention patterns, the other watches layer-wise prediction changes. Neither modifies the model.
Comparison
| Method | Signal | Mechanism |
|---|---|---|
| DoLa | Layer logits (2 layers) | Subtract early from final |
| SLED | Layer logits (all layers) | Gradient refinement |
| DELTA | Masked vs. full input | Subtract masked output |
| Lookback Lens | Attention weights | Detect + penalize |
| Think@n | Layer-wise divergence | Filter best samples |
The first three modify the output distribution per-token. Lookback Lens detects hallucinations per-token. Think@n operates per-sample.
Reading these papers in sequence, you can see the ideas build on each other. DoLa showed that layer contrasting works. SLED showed that using all layers beats picking two. DELTA showed the same contrasting trick works across inputs, not just layers. Lookback Lens showed that attention patterns alone carry enough signal to catch hallucinations. And Think@n closed the loop by showing that these layer-wise signals predict reasoning quality and can cut inference costs in half.
What I keep coming back to is how all five methods exploit the same thing: the evolution of representations across layers encodes factual confidence. If you’re working on uncertainty estimation or robustness, these are worth paying attention to. They give you interpretable confidence signals with zero additional training, and they could slot into existing uncertainty quantification setups without much friction.
References
- Chen, W.-L., & others. (2026). Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens. ArXiv Preprint ArXiv:2602.13517. https://arxiv.org/abs/2602.13517
- Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., & others. (2025). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43(2), 1–55.
- Huang, C. P., & Chen, H.-Y. (2025). Delta – Contrastive Decoding Mitigates Text Hallucinations in Large Language Models. ArXiv Preprint ArXiv:2502.05825. https://arxiv.org/abs/2502.05825
- Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R., & Herzig, J. (2024). Does fine-tuning LLMs on new knowledge encourage hallucinations? ArXiv Preprint ArXiv:2405.05904.
- Shi, W., Han, X., Lewis, M., Tsvetkov, Y., Zettlemoyer, L., & Yih, W.-tau. (2024). Trusting your evidence: Hallucinate less with context-aware decoding. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), 783–791.
- Zhang, J., Juan, D.-C., Rashtchian, C., Ferng, C.-S., Jiang, H., & Chen, Y. (2024). SLED: Self Logits Evolution Decoding for Improving Factuality in Large Language Models. Advances in Neural Information Processing Systems (NeurIPS). https://arxiv.org/abs/2411.02433
- Chuang, Y.-S., Xie, Y., Luo, H., Kim, Y., Glass, J., & He, P. (2024). DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2309.03883
- Chuang, Y.-S., Qiu, L., Hsieh, C.-Y., Krishna, R., Kim, Y., & Glass, J. (2024). Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1419–1436. https://arxiv.org/abs/2407.07071
- Stahlberg, F., & Byrne, B. (2019). On NMT search errors and model errors: Cat got your tongue? ArXiv Preprint ArXiv:1908.10090.