Explaining PackNet Adding Multiple Tasks to a Single Network by Iterative Pruning
Paper Review ·In this paper (Mallya & Lazebnik, 2017), they discuss a method for adding and supporting multiple tasks in a single architecture without having to worry about catastrophic forgetting . They show in this paper that three fine-grained classification tasks can be added to a single ImageNet trained VGG-16 network with comparable accuracies to training a network for each task separately.
What is Lifelong learning ?
Lifelong learning aka continual learning is a domain where we try to create an agent able to acquire expertise on different set of tasks without forgetting previously learnt tasks.
This can be considered as general artificial intelligence as we try to create agents having the ability of humans to learn new tasks (e.g. walking, running, swimming etc…) without forgetting previously acquired tasks (futuristic).
In this setup, data from previous tasks are not seen in later tasks which would cause a catastrophic forgetting when a new task arrives to the model (which means he will get super low accuracies on previous tasks).
In this paper, it resides under the family of parameter isolation-based methods that tries to fix a set of parameters for each task. When you train a task A, it would freeze a set of weights and train the other which would ensure that your model won’t forget what he learnt for a previous arbitrary task B.
What is PackNet ?
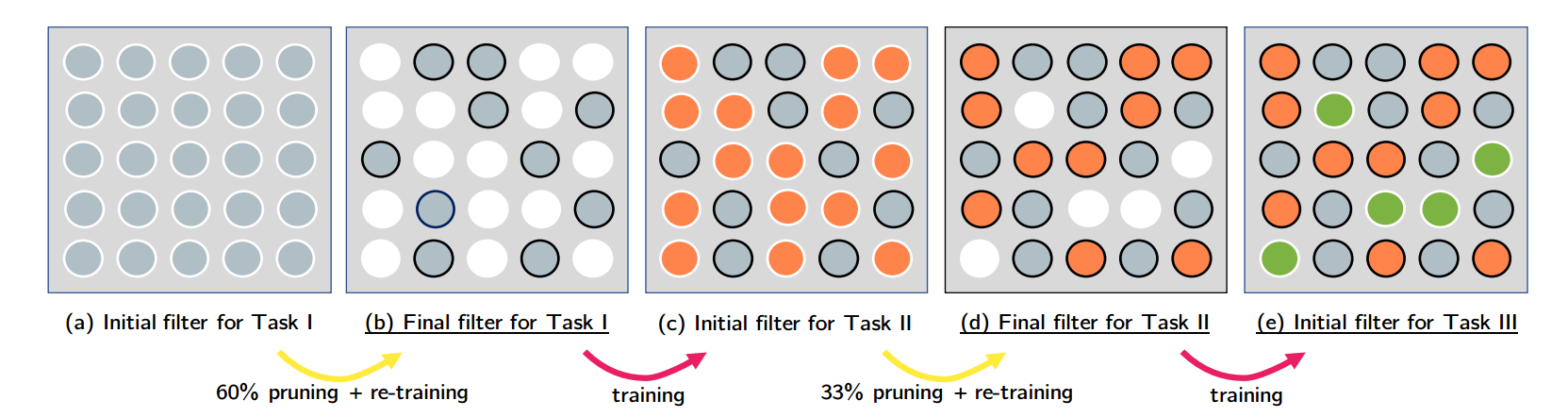
PackNet is a framework that fits a set of tasks into a single architecture by iterative masking a set of weights with marginal loss in accuracy from the first task and using them for the newly added tasks.
For example in the above illustration, We train a dense filter using data from the first Task I.
After training the dense filter we prune the model with 60% and set the weights to zero. Weights kept are selected based on its magnitude (weights with higher magnitude means they are important to the current task). After fixing the important weights for Task I, we start re-training the pruned weights on new added Task II.
Now we have a new task III, we do the same steps by pruning non-critical weights to both task II and task I weight are not considered for pruning. Using the non-critical weights to fit it on the new task III.
Motivation
This work was motivated by compression techniques proposed by (Han et al., 2016), he showed that neural models are over-parameterized and that there exist a sparse sub-network that when retrained achieve same/better performance than the non-sparsified model.
In this line of work they prune the model based on the weight magnitude and re-train.
Approach
The approach consists of iteratively training on a task then pruning some of the parameters to use them for the new task without dramatically forgetting the first task.
Iterative steps applied when new task B comes while having task A:
Training phase: They start with pre-trained ImageNet VGG-16 model, in that case ImageNet is task A.Pruning Step: After training on task A, they remove a fixed percentage of parameters using absolute magnitude. The weights having higher magnitude means they are critical to the model. They prune lowest 50% for example of the weights . Pruning these weights would result in a loss in the model’s performance. To regain the lost accuracy, the model is retrained on task A.Fitting new task B: we freeze the critical weights for task A selected in the previous step. Now we retrain the model using only the pruned weights from the previous steps while using previous tasks’ parameters for the forward pass.Inference step: When performing inference for a selected task, we use parameters trained for that task along with parameters used for previous ones so the model’s state matches the one learned during training.
The previous steps will be applied to new tasks arriving, but the pruning will try to prune from the weights selected only for the previous task. For example, if a task C arrive we will prune from the weights used by task B only and task A weights will remain fixed.
Experimental Results
| Tasks | Individual Networks | PackNet pruning (0.5,0.75,0.75) |
|---|---|---|
| Top-1 Error | ||
| ImageNet | 28.42 | 29.33 |
| Cubs | 22.57 | 25.72 |
| Stanford Cars | 13.97 | 18.08 |
| Flowers | 8.65 | 10.05 |
In their experiments, they start with VGG-16 pre-trained on Image-Net 1000 class, then the next tasks are Cubs dataset, Stanford cars dataset and flowers dataset .
The experimental setup from the paper:
In the case of the Stanford Cars and CUBS datasets, we crop object bounding boxes out of the input images and resize them to 224 × 224. For the other datasets, we resize the input image to 256 × 256 and take a random crop of size 224 × 224 as input. For all datasets, we perform left-right flips for data augmentation.
In all experiments, we begin with an ImageNet pre-trained network, as it is essential to have a good starting set of parameters. The only change we make to the network is the addition of a
new output layer per each new task. After pruning the initial ImageNet pre-trained network, we fine-tune it on the ImageNet dataset for 10 epochs with a learning rate of 1e-3 decayed by a factor of 10 after 5 epochs.
Constructive feedback
The idea of using one shot compression techniques to choose which parameters to fit for which task is a good strategy but the drawbacks of the proposed method can be:
Training time: each iteration of new task you have to prune and re-train on the previous task which is expensive in terms of computational timeFinite number of tasks: what if all the weights are critical for the last task ? This means we won’t be able to prune weights for the new task without losing dramatically the predictive capacity of the model. Also, we are keeping weights from all previous tasks which limits the number of parameters we can prune.
Side Note
I would recommend reading the paper itself and checking the related work, this is just a summary to give you a rough idea of what is going on. Also if you are interested in continual learning check Continual learning course from Universite de Montreal
References
- Mallya, A., & Lazebnik, S. (2017). PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning. CoRR, abs/1711.05769. http://arxiv.org/abs/1711.05769
- Han, S., Pool, J., Narang, S., Mao, H., Tang, S., Elsen, E., Catanzaro, B., Tran, J., & Dally, W. J. (2016). DSD: Regularizing Deep Neural Networks with Dense-Sparse-Dense Training Flow. CoRR, abs/1607.04381. http://arxiv.org/abs/1607.04381